Before Bridge I was CPO at an enterprise SaaS. We had auth, subscriptions, RBAC, all of it working cleanly for the case we'd built for: human users logging into a dashboard.
Then customers started asking if their AI agents could use our product on their behalf. And nothing we had fit.
Agents don't navigate UIs. They don't read your docs. They don't know which endpoint to call for what. They need a discoverable surface, machine-readable schemas, agent-scoped auth, and rate limits that make sense when one customer's agent fires a thousand calls in a minute. That's a whole second stack sitting on top of the one we already had.
I scoped it honestly and the answer was depressing: months of infra work for something that wasn't our core product. So I left and built the layer I kept needing.
Since starting Bridge I've now had a version of that same conversation with dozens of founders and heads of product. Same surprise, same Jira ticket, same quarter that gets eaten. If you're staring at it right now, here's how I'd think about the decision.
What actually changed
For most of the last decade "AI integration" meant putting a chatbot on your marketing site. That's not what your customers want anymore. They want to use your product from inside the chat tool they already have open, which is usually Claude or ChatGPT.
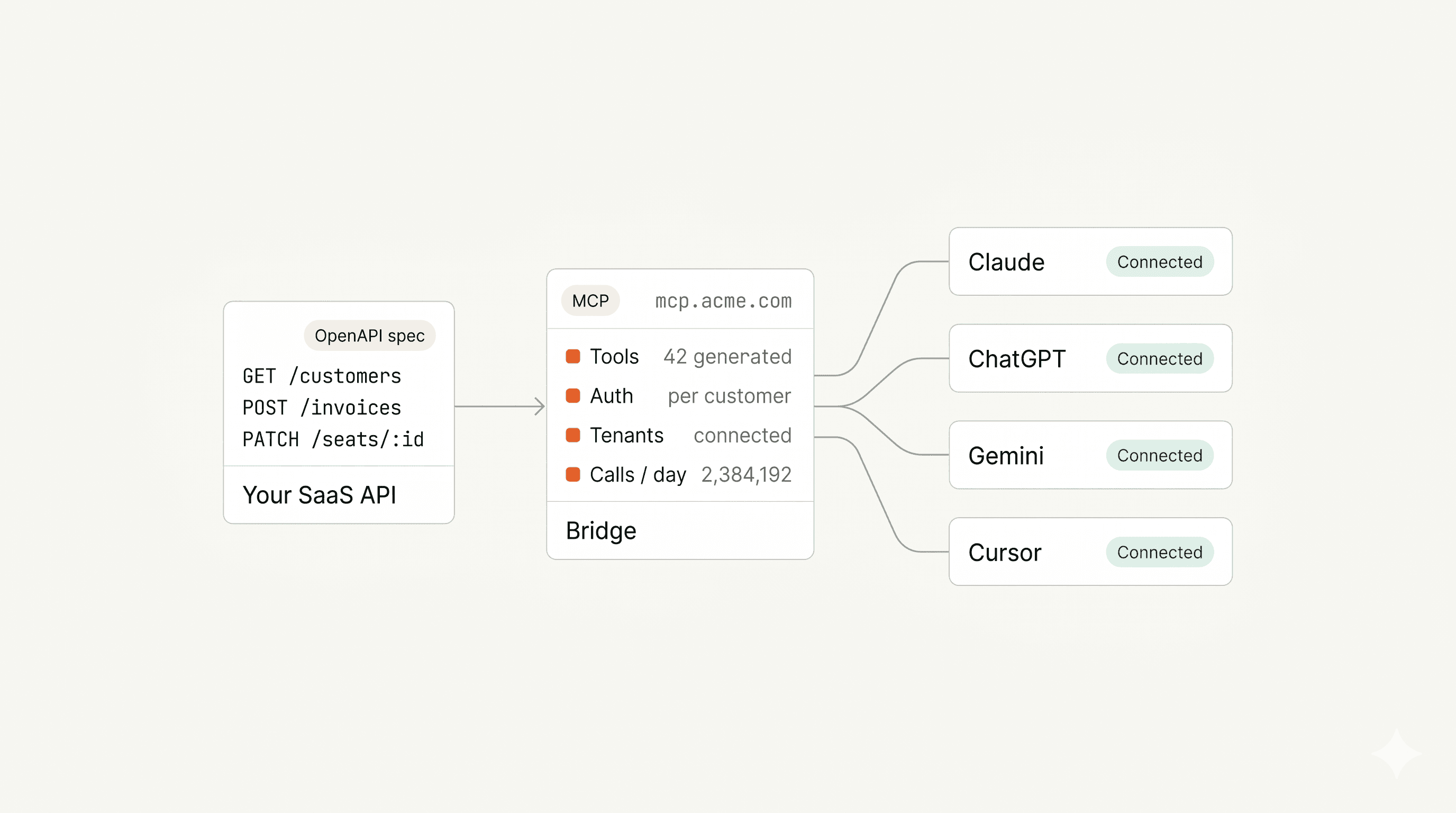
The protocol question used to be hard. Now it isn't. OpenAI and Anthropic both shipped native support for the Model Context Protocol (MCP) in 2024 and 2025. Google followed. Cursor and the rest of the dev-tool ecosystem followed. MCP is "USB-C for AI": one open spec, one server, every client.
So the which protocol question has an answer: MCP. The harder question is how to expose your product through it. That's where the three paths split.
Path 1 — Build it yourself
You write an MCP server in TypeScript, Python, or Go. You implement the JSON-RPC transport, define your tools, wire them to your API handlers, deploy it. On paper, a normal engineering project.
It is not a normal engineering project. Our CTO Tomer wrote a long post on what we learned shipping production MCP infrastructure, and the headline lesson is the one I keep watching other founders bounce off: OpenAPI-to-MCP conversion takes a day. The auth takes a quarter.
OAuth 2.1 plus PKCE plus the RFC 9728 metadata spec. Per-tenant credential vaults so the LLM never sees your upstream keys. Per-customer scoping so a tool call by Customer A never returns Customer B's data. Tool descriptions tuned for the model, because if you just auto-generate them from your OpenAPI summaries the LLM picks the wrong tool roughly half the time. Tool grouping done correctly, which sounds easy and isn't (Tomer wrote a on why the obvious approach fails).