What I Learned Building a Managed MCP Infrastructure Layer — Auth, Credential Injection, and the Stuff No One Talks About
After spending weeks building production MCP infrastructure, here are the decisions that mattered most — and the ones I'd do differently. What started as a Reddit post became a surprisingly deep conversation with other builders fighting the same battles. This is the expanded version, with community insights woven in.
1. OpenAPI → MCP conversion is the easy part. Auth is the hard part.
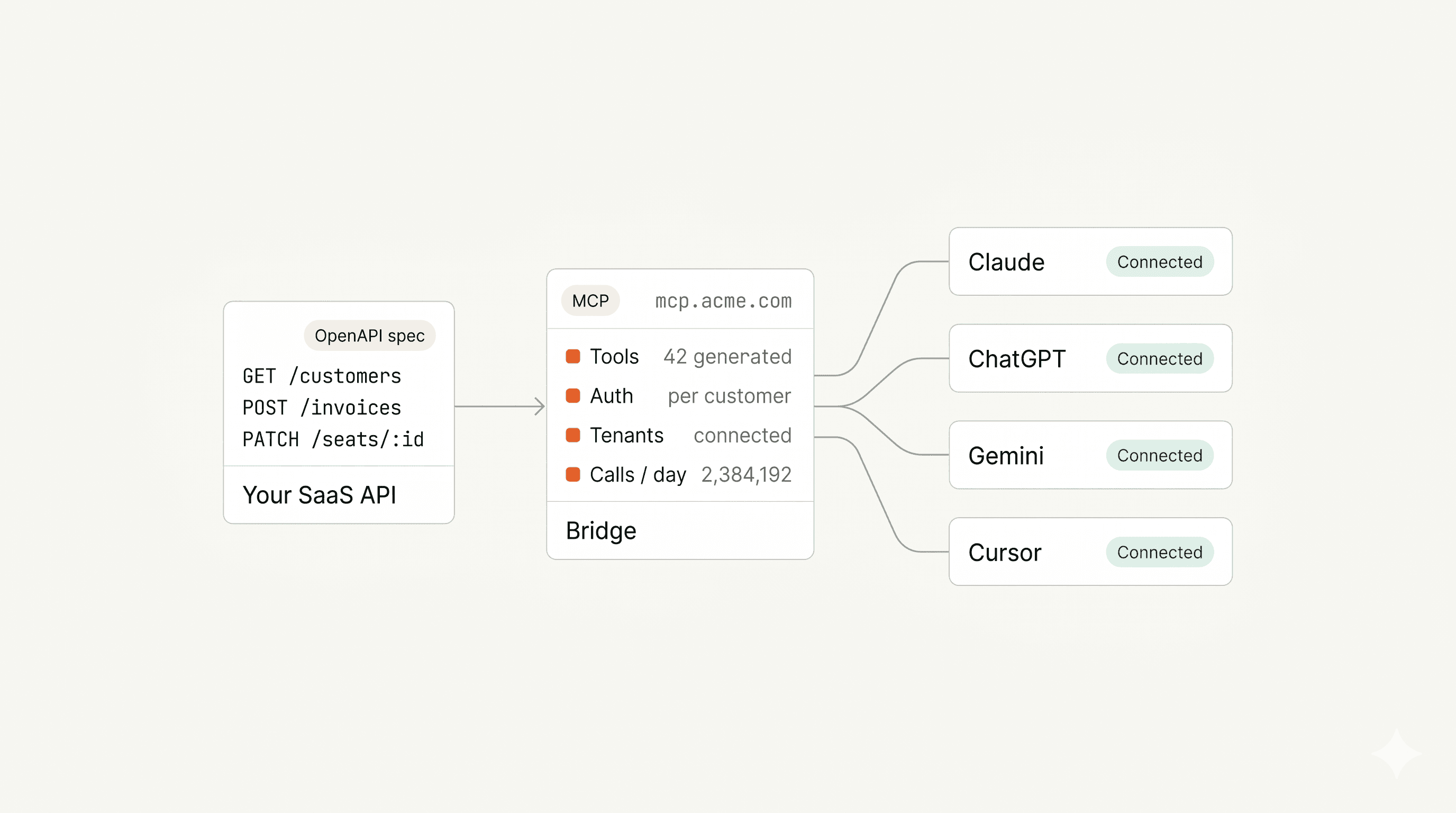
Auto-generating MCP manifests from OpenAPI specs is straightforward. Map paths to tools, extract schemas, it's a one minute job. The real complexity turned out to be auth. OAuth 2.1 + RFC 9728 (PRM) + PKCE are specs you need to get right before a single tool call works.
If you're building multiple MCP servers, do NOT implement OAuth in each one. Centralize it. One gateway. One place to get it right.
The community validated this. One builder shipping a game-server hosting platform via agents told me auth took "3x the time of everything else on the API combined." Another pointed out that even managed platforms like AWS AgentCore split auth into two categories — inbound (user → gateway) and outbound (gateway → target) — with completely different approaches for each. The consensus: auth eats your roadmap if you are not careful.
2. Credential injection is the right pattern.
Never let the MCP client see the upstream API key. Issue each end user their own OAuth client_id / client_secret. The dispatch layer validates the OAuth token, looks up the user's encrypted credential, decrypts it, and injects it into the upstream request. The MCP server is a proxy — it receives identity headers and forwards to the API.
Benefits:
- Per-user revocation
- Per-user rate limiting.
- Audit trail
- Credential rotation without touching client configs.
One community member took this further: for agents that can trigger financial transactions (provisioning servers, placing orders), they issue per-session tokens with a pre-authorized spend cap and TTL. The agent never sees the actual payment method. If the agent goes off the rails — purchase loops, wrong region, wrong tier — the cap blocks it before the card auth call fires. Same pattern, bounded by spend rather than time.
OpenMM (open-source MCP for financial exchanges) added another layer: per-tool credential tagging. If place_order needs a different OAuth scope than read_positions, the manifest declares it, and the dispatch layer negotiates which credential to inject per tool call rather than per session. The MCP server stays stateless; the gateway does the thinking.